
IDG Contributor Network: The clash of big data and the cloud
Recently, I visited a few conferences and I noticed a somewhat hidden theme. While a lot of attention was being paid to moving to a (hybrid) cloud-based architecture and what you need for that (such as cloud management platforms), a few presentations showed an interesting overall development that everybody acknowledges but that does not get a lot of close attention: the enormous growth of the amount of digital data stored in the world.
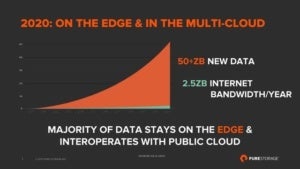
What especially caught my attention was a presentation from PureStorage (a storage vendor) that combined two data points from two other vendors. First, a June 2017 Cisco white paper The Zettabyte Era: Trends and Analysis that extrapolates the growth of internet bandwidth, the second a Seagate-sponsored IDC study Data Age 2025 that extrapolates the trend of data growth in the world. PureStorage combined both extrapolations in the following figure (reused with permission):
 PureStorage
PureStorage
PureStorage’s depiction of the clash between world data growth and world internet bandwidth growth.
These trends—if they become reality, and there are reasons enough to think these predictions to be reasonable—are going to have a major impact of the computing and data landscapes in the years to come. And they will especially impact the cloud hoopla that is still in full force. Note: The cloud is real and will be an important part of future IT landscapes, but simplistic ideas about it being a panacea for every IT ailment are strongly reminiscent of the “new economy” dreams of the dot-com boom. And we know how that ended.
The inescapable issue
Anyway, there are two core elements of all IT: the data and the logic working with/on the data. Big data is not just about the data. Data is useless (or as Uncle Ludwig would have it: meaningless) unless it can be used. What everybody working with big data already knows: To use huge amounts of data, you need to bring the processing to the data and not the data to the processing. Having the processing at any “distance” creates such a transport bottleneck that performance decreases to almost nothing and any function of that logic becomes a purely theoretical affair.
Even with small amounts of data, this already may happen because of latency. For instance, moving your application server to the cloud while retaining your database server on premises may work on paper, but when the application is sensitive to latency between it and the database it doesn’t work at all. And that can already be the case for small amounts of data. This is why many organizations are trying to adapt software so it becomes less latency-sensitive, thus enabling a move into the cloud. But with huge amounts of data, you need to bring processing and data close to each other, else it just does not work. Add the need for massive parallelism to handle that data and you get Hadoop and other architectures that tackle the problem of processing huge amounts of data.
Now, the amount of data in the world is growing exponentially. If IDC is to be believed, in a few years’ time, the world is expected to store about 50ZB (zettabytes), or 50,000,000,000,000,000,000,000 bytes). On the other hand, while the total capacity of the Internet to move data around grows too, it does at a far more leisurely pace. In the same period that world data size grows to 50ZB, the total internet bandwidth will reach something like 2.5ZB per year (if Cisco is to be believed).
The conclusion from those two (not unreasonable) expectations is that the available internet bandwidth is by far not enough to move a sizeable fraction of the data around. And that is ignoring even the fact that about 80 percent of the current bandwidth is used for streaming video. So, even if you have coded your way around the latency issues in your core application, for cases with larger amounts of data, there will be a bandwidth issue as well.
Now, is this issue actually a problem? Not if the processing or use of that data happens locally—that is, in the same datacenter that holds the data. But while on the one hand the amount of data is growing exponentially, the world is also aggressively pursuing cloud-strategies; that is, to put all kind of workloads to the cloud, in the absolute extremes even “serverless” (for example, AWS Lambda).
Assuming that only small-sized results (calculated from huge data sets) may move around probably only helps a bit, because the real value of huge amounts of data comes from combining them. And that may mean combining data from different owners (your customer records with a feed from Twitter, for instance). It is the aggregation of all that different sets that is the issue.
So, what we see is two opposing developments. On the one hand, everybody is busy adapting to a cloud-based architecture that in the end is based on distributed processing of distributed data. On the other and, the amount of data we use is getting so large that we have to consolidate data and its processing in a single physical location.
So, what does that imply?
Well, we may expect that what Hadoop does at the application architecture level will also happen on a world level: the huge data sets will be attractors for the logic that make them meaningful. And those huge data sets will gravitate together.
Case in point: Many are now scrambling to minimize the need to move that data around. So, in the IoT world there is a lot of talk about edge computing: handling data locally where the sensors and other IoT devices are. Of course, what that also means is that the processing must also be locally, and you can safely assume that you will not be bringing the same level of computing power to bear in a (set of) sensors than what you can do in big analytics setups. Or: you probably won’t see a Hadoop cluster under the hood of your car anytime soon. So, yes, you can minimize data traffic that way, but at the expense of how much you can compute.
There is another solution for this issue: Stick together in datacenters. And that is also what I see happening. Colocation providers are on the rise. They offer large datacenters with optimized internal traffic capabilities where both cloud providers and large cloud users are sticking together. Logically, you may be in the cloud, but physically you are on the same premises as your cloud provider. You don’t want to run your logic just on AWS or Azure; you want to do that in a datacenter where you also have your own private data lake so all data is local to the processing and data aggregation is local as well. I’ve written elsewhere (Reverse Cloud | Enterprise Architecture Professional Journal) on the possibility that cloud providers might be extending into your datacenters, but the colocation pattern is another possible solution for solving the inescapable bandwidth and latency issues arising from the exponential growth of data.
The situation may not be as dire as I’m sketchinf it. For example, maybe the actual average volatility of all that data will ultimately be very low. On the other hand, you would not want to run your analytics on stale data. But one conclusion can be drawn already: Simply assuming that you can distribute your workloads to a host of different cloud providers (the “cloud … yippy!” strategy) is risky, especially if at the same time the amount of data you are working with grows exponentially (which it certainly will, if everyone wants to combine their own data with streams from Twitter, Facebook, etc., let alone if those combinations spawn all sorts of new streams).
Therefore, making good strategic design decisions (also known as “architecture”) about the locations of your data and processing (and what can and can’t be isolated from other data and) is key. Strategic design decisions … hmm that sounds like a job for architecture.
This article is published as part of the IDG Contributor Network. Want to Join?
Source: InfoWorld Big Data