
How to use Apache Kafka messaging in .Net
Apache Kafka is an open source, distributed, scalable, high-performance, publish-subscribe message broker. It is a great choice for building systems capable of processing high volumes of data. In this article we’ll look at how we can create a producer and consumer application for Kafka in C#.
To get started using Kafka, you should download Kafka and ZooKeeper and install them on your system. This DZone article contains step-by-step instructions for setting up Kafka and ZooKeeper on Windows. When you have completed the setup, start ZooKeeper and Kafka and meet me back here.
Apache Kafka architecture
In this section, we will examine the architectural components and related terminology in Kafka. Basically, Kafka consists of the following components:
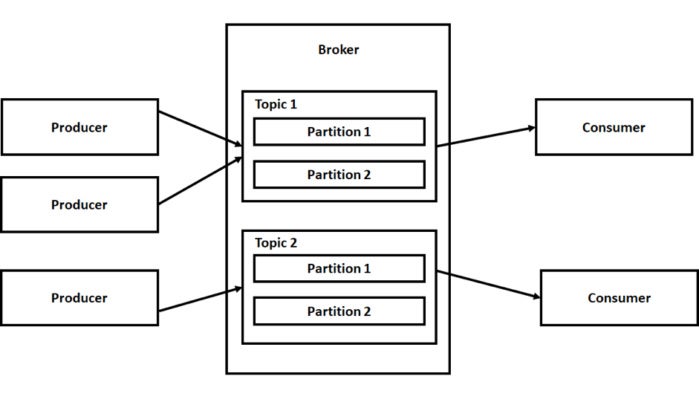
- Kafka Cluster—a collection of one or more servers known as brokers
- Producer – the component that is used to publish messages
- Consumer – the component that is used to retrieve or consume messages
- ZooKeeper – a centralized coordination service used to maintain configuration information across cluster nodes in a distributed environment
The fundamental unit of data in Kafka is a message. A message in Kafka is represented as a key-value pair. Kafka converts all messages into byte arrays. It should be noted that communications between the producers, consumers, and clusters in Kafka use the TCP protocol. Each server in a Kafka cluster is known as a broker. You can scale Kafka horizontally simply by adding additional brokers to the cluster.
The following diagram illustrates the architectural components in Kafka – a high level view.
 Apache FOUNDATION
Apache FOUNDATION
A topic in Kafka represents a logical collection of messages. You can think of it as a feed or category to which a producer can publish messages. Incidentally, a Kafka broker contains one or more topics that are in turn divided into one or more partitions. A partition is defined as an ordered sequence of messages. Partitions are the key to the ability of Kafka to scale dynamically, as partitions are distributed across multiple brokers.
You can have one or more producers that push messages into a cluster at any given point of time. A producer in Kafka publishes messages into a particular topic, and a consumer subscribes to a topic to receive the messages.
Choosing between Kafka and RabbitMQ
Both Kafka and RabbitMQ are popular open source message brokers that have been in wide use for quite some time. When should you choose Kafka over RabbitMQ? The choice depends on a few factors.
RabbitMQ is a fast message broker written in Erlang. Its rich routing capabilities and ability to offer per message acknowledgments are strong reasons to use it. RabbitMQ also provides a user-friendly web interface that you can use to monitor your RabbitMQ server. Take a look at my article to learn how to work with RabbitMQ in .Net.
However, when it comes to supporting large deployments, Kafka scales much better than RabbitMQ – all you need to do is add more partitions. It should also be noted that RabbitMQ clusters do not tolerate network partitions. If you plan on clustering RabbitMQ servers, you should instead use federations. You can read more about RabbitMQ clusters and network partitions here.
Kafka also clearly outshines RabbitMQ in performance. A single Kafka instance can handle 100K messages per second, versus closer to 20K messages per second for RabbitMQ. Kafka is also a good choice when you want to transmit messages at low latency to support batch consumers, assuming that the consumers could be either online or offline.
Building the Kafka producer and Kafka consumer
In this section we will examine how we can build a producer and consumer for use with Kafka. To do this, we will build two console applications in Visual Studio – one of them will represent the producer and the other the consumer. And we will need to install a Kafka provider for .Net in both the producer and the consumer application.
Incidentally, there are many providers available, but in this post we will be using kafka-net, a native C# client for Apache Kafka. You can install kafka-net via the NuGet package manager from within Visual Studio. You can follow this link to the kafka-net GitHub repository.
Here is the main method for our Kafka producer:
static void Main(string[] args)
{
string payload ="Welcome to Kafka!";
string topic ="IDGTestTopic";
Message msg = new Message(payload);
Uri uri = new Uri(“http://localhost:9092”);
var options = new KafkaOptions(uri);
var router = new BrokerRouter(options);
var client = new Producer(router);
client.SendMessageAsync(topic, new List<Message> { msg }).Wait();
Console.ReadLine();
}
And here is the code for our Kafka consumer:
static void Main(string[] args)
{
string topic ="IDGTestTopic";
Uri uri = new Uri(“http://localhost:9092”);
var options = new KafkaOptions(uri);
var router = new BrokerRouter(options);
var consumer = new Consumer(new ConsumerOptions(topic, router));
foreach (var message in consumer.Consume())
{
Console.WriteLine(Encoding.UTF8.GetString(message.Value));
}
Console.ReadLine();
}
Note that you should include the Kafka namespaces in both the producer and consumer applications as shown below.
using KafkaNet;
using KafkaNet.Model;
using KafkaNet.Protocol;
Finally, just run the producer (producer first) and then the consumer. And that’s it! You should see the message “Welcome to Kafka!” displayed in the consumer console window.
While we have many messaging systems available to choose from—RabbitMQ, MSMQ, IBM MQ Series, etc.—Kafka is ahead of the pack for dealing with large streams of data that can originate from many publishers. Kafka is often used for IoT applications and log aggregation and other use cases that require low latency and strong message delivery guarantees.
If your application needs a fast and scalable message broker, Kafka is a great choice. Stay tuned for more posts on Kafka in this blog.
Source: InfoWorld Big Data